Document Search Engine
Architecture. Although the architectures of different Web search engines may vary, a typical document search engine generally consists of the following four main components as shown in Fig. 1: Web crawler, Indexer, Index database, and Query engine. A Web crawler, also known as a Web spider or a Web robot, traverses the Web to fetch Web pages by following the URLs of Web pages.
The Indexer is responsible for parsing the text of each Web page into word tokens and then creating the Index database using all the fetched Web pages. When a user query is received, the Query engine searches the Index database to find the matching Web pages for the query.
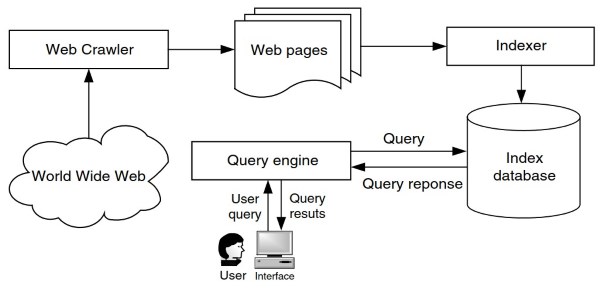
Figure 1. The general architecture of a document search engine
Crawling the Web. A Web crawler is a computer program that fetches Web pages from remote Web servers. The URL of each Web page identifies the location of the page on the Web. Given its URL, a Web page can be downloaded from a Web server using the HTTP (Hyper Text Transfer Protocol). Starting from some initial URLs, a Web crawler repeatedly fetches Web pages based on their URLs and extracts new URLs from the downloaded pages so that more pages can be downloaded.
This process ends when some termination conditions are satisfied. Some possible termination conditions include no new URL remains and a preset number of pages have been downloaded. As a Web crawler may interact with numerous autonomous Web servers, it is important to design scalable and efficient crawlers.
To crawl the Web quickly, multiple crawlers can be applied. These crawlers may operate in two different manners (i.e., centralized and distributed). Centralized crawlers are located at the same location running on different machines in parallel. Distributed crawlers are distributed at different locations of the Internet, and controlled by a central coordinator; each crawler just crawls the Web sites that are geographically close to the location of the crawler. The most significant benefit of distributed crawlers is the reduction in communication cost incurred by crawling activity. Centralized crawlers, however, are easier to implement and control than distributed crawlers.
As the Web grows and changes constantly, it is necessary to have the crawlers regularly re-crawl the Web and make the contents of the index database up to date. Frequent re-crawling of the Web will waste significant resources and make the network and Web servers overloaded.
Therefore, some incremental crawling strategies should be employed. One strategy is to re-crawl just the changed or newly added Web pages since the last crawling. The other strategy is to employ topic-specific crawlers to crawl the Web pages relevant to a pre-defined set of topics. Topic-specific crawling can also be used to build specialized search engines that are only interested in Web pages in some specific topics.
Conventional Web crawlers are capable of crawling only Web pages in the Surface Web. Deep Web crawlers are designed to crawl information in the Deep Web. As information in the Deep Web is often hidden behind the search interfaces of Deep Web data sources, Deep Web crawlers usually gather data by submitting queries to these search interfaces and collecting the returned results.
Indexing Web Pages. After Web pages are gathered to the site of a search engine, they are pre-processed into a format that is suitable for effective and efficient retrieval by search engines. The contents of a page may be represented by the words it has. Non-content words such as ‘‘the’’ and ‘‘is’’ are usually not used for page representation. Often, words are converted to their stems using a stemming program to facilitate the match of the different variations of the same word. For example, ‘‘comput’’ is the common stem of ‘‘compute’’ and ‘‘computing’’.
After non-content word removal and stemming are performed on a page, the remaining words (called terms or index terms) are used to represent the page. Phrases may also be recognized as special terms. Furthermore, a weight is assigned to each term to reflect the importance of the term in representing the contents of the page.
The weight of a term t in a page p within a given set P of pages may be determined in a number of ways. If we treat each page as a plain text document, then the weight of t is usually computed based on two statistics. The first is its term frequency (tf) inp (i.e., the number of times t appears in p), and the second is its document frequency (df) in P (i.e., the number of pages in P that contain t). Intuitively, the more times a term appears in a page, the more important the term is in representing the contents of the page.
Therefore, the weight of t in p should be a monotonically increasing function of its term frequency. On the other hand, the more pages that have a term, the less useful the term is in differentiating different pages. As a result, the weight of a term should be a monotonically decreasing function of its document frequency.
Currently, most Web pages are formatted in HTML, which contains a set of tags such as title and header. The tag information can be used to influence the weights of the terms for representing Web pages. For example, terms in the title of a page or emphasized using bold and italic fonts are likely to be more important in representing a page than terms in the main body of the page with normal font.
To allow efficient search of Web pages for any given query, the representations of the fetched Web pages are organized into an inverted file structure. For each term t, an inverted list ofthe format [(p1, w1),..., (pk, wk)] is generated and stored, where each pj is the identifier of a page containing t and wj is the weight of t in pj, 1≤j≤k. Only entries with positive weights are kept.
Date added: 2024-07-23; views: 550;