What Is Cardiovascular Genomics?
Genomics involves comprehensive analysis of the genetic make-up and variation for a species in order to better understand both normal biology and the relationship between genetic variation and risk of disease. It takes a “wide-view” of the potential impact of genetic variation on health and disease, seeking to understand the potential influence of multiple, concomitant genetic variations (compared to single, high-impact, monogenic variations) on determining the phenotype and health of an organism. Genomics has grown out of efforts to fully define the human genome, beginning with completion of the Human Genome Project in 2003.
Multiple efforts to catalog variation in the human genome have included The Single Nucleotide Polymorphism (SNP) Consortium, the International HapMap Project, and the 1000 Genomes Project. The field of cardiovascular genomics involves studying the influence of genetic variation on cardiovascular disease (CVD) risk. Examining the human genome for factors contributing to CVD risk has led to the discovery of SNPs which increase the risk of CVD. Through experiments such as genome-wide association studies (GWAS) and Mendelian randomization, investigators have recently linked particular SNPs to clinical CVD phenotypes.
Identification of the links between genetic variants and CVD has also allowed for the development of “risk scores,” which estimate the CVD risk resulting from the presence of multiple SNPs. Such studies have also led to the identification of potential targets for pharmacotherapy in lipidology and CVD. Recent advances in cardiovascular genomics have been facilitated by the development of newer tools for gene sequencing. The automated Sanger method has been largely replaced by newer technologies which can perform gene sequencing more quickly and cost-effectively. These newer technologies are collectively referred to as next-generation sequencing (NGS).
Two commonly used methods for analyzing the potential genetic contribution to CVDs are GWAS and Mendelian randomization. GWAS involves measuring the frequency of genetic variations (such as SNPs) in individuals with a disease and comparing these individuals to healthy controls. This method allows for exploring associations between an increased frequency of a genetic variant and a particular disease phenotype, such as CVD. An early example of GWAS in CVD involved analysis of 92,788 SNPs to identify a locus on chromosome 6p21 associated with an increased risk of myocardial infarction, while a recent GWAS in a large cohort of 312,571 genotyped participants from the Million Veteran Program examined genetic variants (~32 million) for their association with lipid metabolism and risk of CVD in 297,626 participants with known lipid values.
A GWAS in >100,000 individuals identified 95 loci implicated in lipid metabolism, and in some cases, risk of CVD. At the time of publication in 2010, these investigators confirmed the association between lipids and 36 SNPs identified previously and reported associations between lipids and 59 SNPs for the first time (including in the genes LDLRAP1, SCARB1, NPC1L1, MYLIP, and PPP1R3B). Such GWASs identify candidate loci to test in Mendelian randomization studies.
Mendelian randomization is an experimental design in which outcomes among individuals with a genetic variant of interest are compared with those among individuals without that genetic variation. Like randomized controlled drug trials in which individuals are randomized to exposure vs control, Mendelian randomization is based on the principle that genotypes are randomly assigned during meiosis; individuals are “randomized” to be exposed to the genetic variant of interest vs not (i.e. the control group) and outcomes can be compared between the two groups.
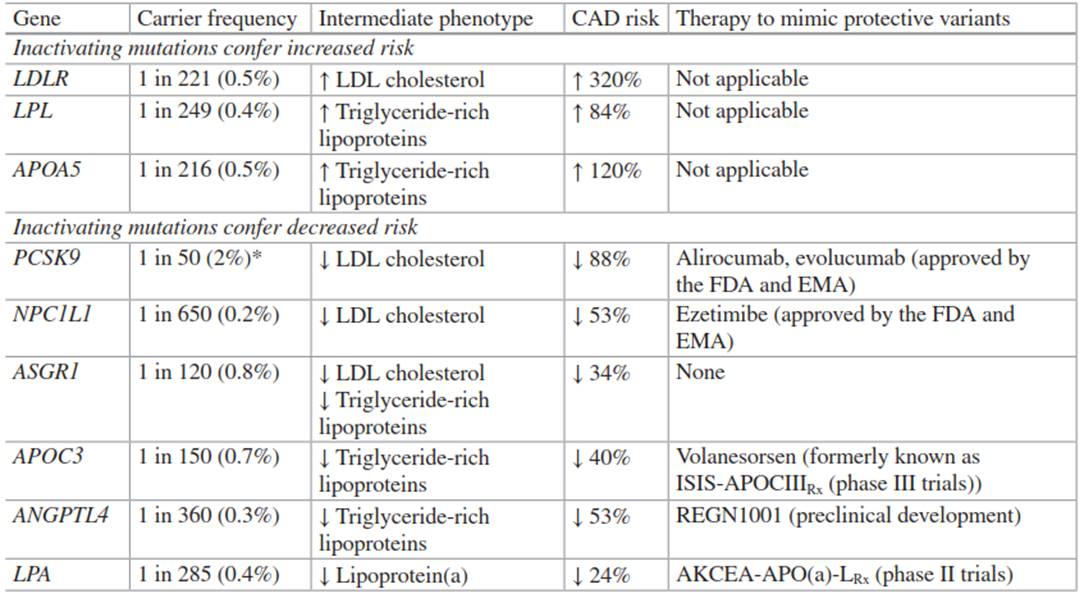
Table 4.1. Summary of the relationship between mutations in nine genes related to lipid metabolism and risk of coronary artery disease (CAD)
This design relies on the quality of gene association studies in order to identify genetic variants of interest to test in these experiments. To date, this approach has led to the identification of many genetic variants implicated in lipid disorders and CVD risk (Table 4.1). This chapter will explore some of the contributions and applications of cardiovascular genomics to the fields of CVD and clinical lipidology through a discussion of the use of cardiovascular genomics to: (1) develop polygenic risk scores, (2) estimate prevalence and CVD risk in familial hypercholesterolemia (FH), (3) define the role of lipoprotein(a) in risk for CVD and aortic valve disease, and (4) identify potential targets for lipid-modifying pharmacotherapy.
Date added: 2025-02-17; views: 539;