A selectively permeable phospholipid membrane
Let us consider an initial situation similar to that described in Figure 3.6, in which a negative nucleus with a high affinity for potassium is immersed in a solution of sodium chloride and potassium chloride, with a concentration ratio of 50 to 1, similar to that of seawater (Table 3.1).
In this hypothetical situation, the protein cluster is surrounded by a phospholipid bilayer membrane with interruptions that constitute non-specific aqueous pores. Through these apertures, water and small ions such as sodium, potassium and chloride can move, even if with a reduced number of degrees of freedom, between 1 and 2 (Figure 3.6).
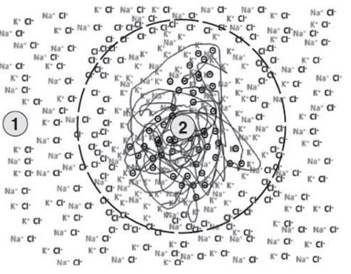
Figure 3.6. The presence of a porous membrane selective only for water and small ions can allow a transient separation of charges, but this is immediately cancelled by the free diffusion of anions and cations
Furthermore, consider the volume of 1 to be infinite compared to the volume of 2. In this case, it is easy to identify 1 as the external side and 2 as the inside of a primordial biological system.
At time zero, the negative fixed charges of the central core have a high probability of being compensated for by potassium ions, due to the high affinity for this ion. Sodium chloride and potassium chloride are present on the outside of the membrane, with a concentration ratio of 50 to 1 as mentioned.
The amount of potassium present on the inside is higher than in 1, but its concentration is low; it is trapped by the high-affinity protein core. Potassium, which enters through the membrane by concentration and electrical gradient, pulls in the chloride ions that are momentarily unbalanced. The charges of the excess chloride ions are readily neutralized by both new potassium ions and sodium ions entering freely into the internal environment. The system as a whole achieves an immediate balance of charges and concentration, even though there is a concentration gradient for the potassium ion.
A system such as that illustrated in Figure 3.6 is still unsuitable for charge separation and the accumulation of energy. Even if a semipermeable separator is present, the general conditions are identical to those described for Figure 3.5.
The small excess of electrical potential due to the imbalance of potassium ions is promptly buffered by other ions. In fact, in an open aqueous environment, i.e., in which water and small molecules diffuse freely, even if locally we can find differences in both ionic concentrations and minimal differences in electric charges, it is not possible to realize a real and consistent accumulation of potential energy.
Accumulation can only be achieved if the system does not establish a static but rather a dynamic equilibrium and if there is a real separation of charges, while respecting the principle of electro-neutrality of solutions. Biological systems have resolved this apparent contradiction by interposing a barrier between the two environments of interest that has very special biophysical characteristics: the plasma membrane.
First of all, the plasma membrane must be a non-rigid structure, in order to cope with volume variations due to the movements of water; these movements are necessarily created to rebalance the osmolarity of the solution following the movement of ions. The membrane must also be, at least as a first approximation, permeable only to water and selected small ions, to prevent free diffusion.
From a strictly functional point of view, it must also have the characteristics of a capacitor, an element that is able to accumulate charges on one side and balance them with opposite charges on the other side (Chapter 2 and Figure 2.5).
Once charged, the membrane capacitor can maintain its charge for an infinite period of time if the dielectric is a perfect insulator: only a short circuit between the two sides of the membrane, resetting the dielectric resistance to zero, would allow the flux to distribute the charges again in a random and homogeneous manner.
Biological membranes can separate opposite charges because lipids are highly hydrophobic, and therefore impermeable to ions. Their thickness, as mentioned above, of 7-10 nanometers, is comparable to the distance between the armatures of a capacitor that accumulates charged particles with dimensions similar to those of ions in biological solutions.
If biological membranes were made up solely of a homogeneous phospholipid bilayer, they would behave like a capacitor, but their function would be only that of an inert barrier. In order for the system to be dynamic and react to changes that may occur on either side of the membrane, it is also necessary to have gaps through which water and selected ionic species can permeate and become distributed in an appropriate manner.
The simultaneous presence of a capacitor in biological membranes, which is able to accumulate charges and offers the possibility of modulating ion permeation, allows not only an accumulation of electrical potential, but also to modulate it according to internal and/or external demands.
Three major points about membrane capacitors should be remembered (Chapter 2.1). The functional contribution of the capacitor occurs only during a change over time of the membrane potential. Furthermore, at time zero, the plasma membrane, behaving as a capacitor, has an electrical resistance equal to zero.
Thus, ionic current, as any dynamic flux, always chooses the lowest resistance path. From a functional point of view, this means that the first choice of any uncompensated charge is to get to the membrane, increasing the number of charges present on the membrane capacitor armatures, thus contributing to modifying the membrane potential.
It should also be remembered that as the charge of the capacitor increases, the probability that other charges of the same sign will be deposited on the armatures decreases, as they are repelled by those already accumulated. From a functional point of view, during voltage transition (dV/dt), the capacitor increases its electrical resistance over time.
In order to have this dual function, as a charge accumulator and as an electrical potential modulator, it is necessary for the membrane not only to play a structural role, but also to assume an active functional role of selective permeability only for small ions. In this case, permeability is for potassium and chloride ions and water, maintaining a low or even zero permeability for all other ions, in particular sodium and calcium. Under these experimental conditions, events take place as described in Figure 3.6.
The excess chloride ions, pulled in by the entry of potassium ions, cannot be counterbalanced by the entry of sodium or calcium, since the membrane is impermeable to these ions. The chloride ions, therefore, follow the path of least resistance, i.e., they settle on the inner face of the membrane capacitor (for example, side A of Figure 2.5) which has, at time zero, zero electrical resistance.
The excess chloride ions can be neutralized by the positive sodium, calcium, and to a small extent, potassium ions, which accumulate on the outer side of the membrane (side B of Figure 2.5). At the end of the process, we have a system in which the membrane has a predominantly negative charge, even if it is only tens of millivolts near the inner face, and a predominantly positive charge near the outer face.
However, considering sufficiently large micro-environments, there is electro-neutrality across the membrane. In addition, both the outside and the inside are in equilibrium chemically and electrically, since the excess of potassium on the inside is compensated for by the accumulation of negative charges on the inside of the membrane and, despite the presence of gaps in the membrane, the net flux across the membrane is zero.
The capacitor-like properties of the membrane enable the effective separation of charges, while respecting the principle of electro-neutrality of the solution, and at the same time enable the accumulation of potential energy as a voltage difference across the membrane; this accumulation only affects the micro-environment close to the membrane.
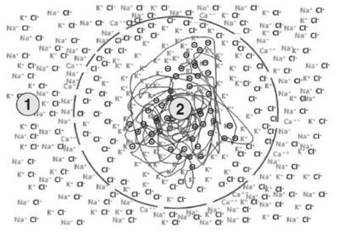
Figure 3.7. The presence of a porous membrane that is selective only for potassium and chloride ions allows the formation of a concentration gradient and an electrical gradient between the external 1 and internal 2 environments
A model such as that shown in Figure 3.7 is capable of producing a momentary separation of charges and does not require the intervention of any form of energy, but only a different combination and distribution in space of the ionic concentrations, charged elements immobilized in one of the two environments and a selectively permeable phospholipid membrane.
This condition is known as Donnan equilibrium (tab. 3.1) and, depending on the cell in question, is responsible for a potential difference across the membrane in the order of -10, -15 mV, with the inside environment negative.
Date added: 2024-07-02; views: 597;